
When Bots Outnumber Humans: Case for Bot Tolls
Non-human bots are overwhelming the internet and accelerating the need for bot tolls to monetize and manage traffic.


Have you recently encountered a “prove you are human” screen when trying to visit a website? It’s a reaction to the sheer amount of non-human bots overwhelming the internet.
Think of today's internet infrastructure like a toll highway. For years, human drivers paid tolls and advertisers paid for billboards. But then driverless cars (the bots) started rolling in. They use these highways, but they bypass tolls and don’t look at billboards. Costs to maintain the increased traffic rise while ad revenue shrinks. This is what we are seeing all across the internet.
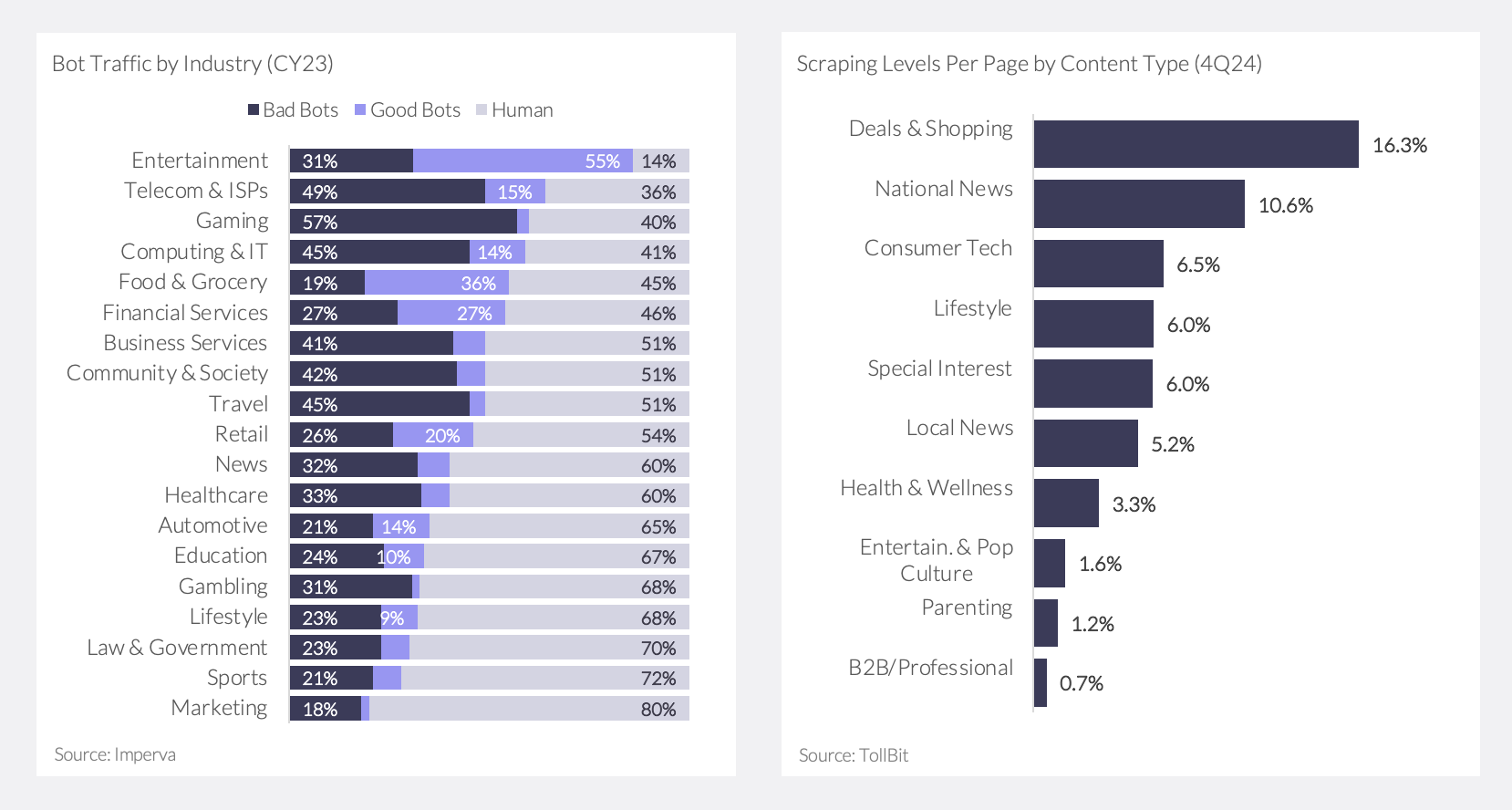
Bot traffic is overshadowing human visitors and now accounts for nearly half of all internet traffic, a jump up from 38% only five years ago (Exhibit 1). In the US, bots made up ~42% of 2024 internet traffic, up from 36% one year prior. Imperva’s analysis reveals that two-thirds of bot traffic comes from “bad bots,” which scrape data without permission or pose cyber security and fraud threats.
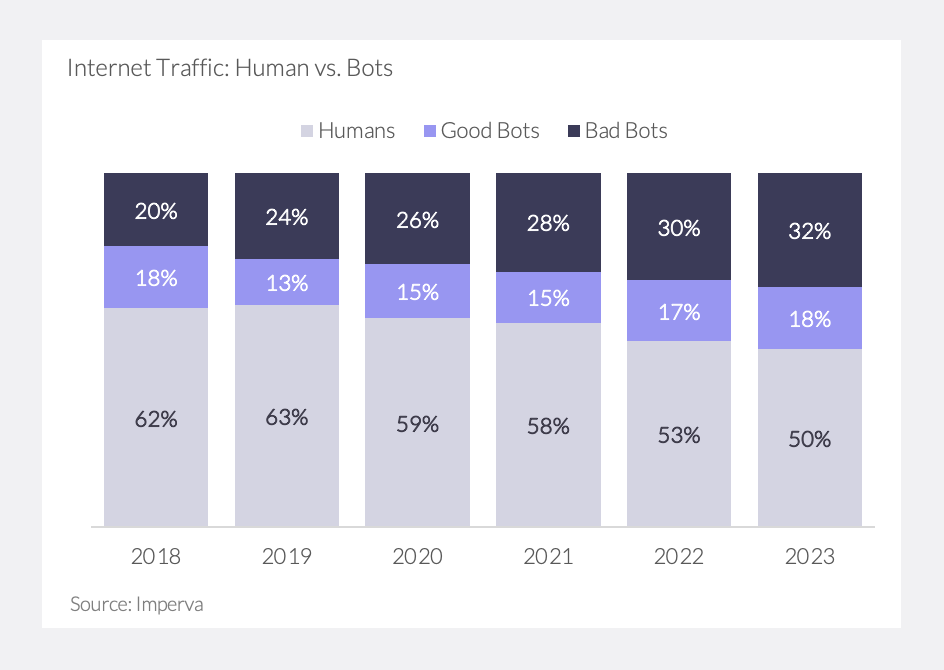
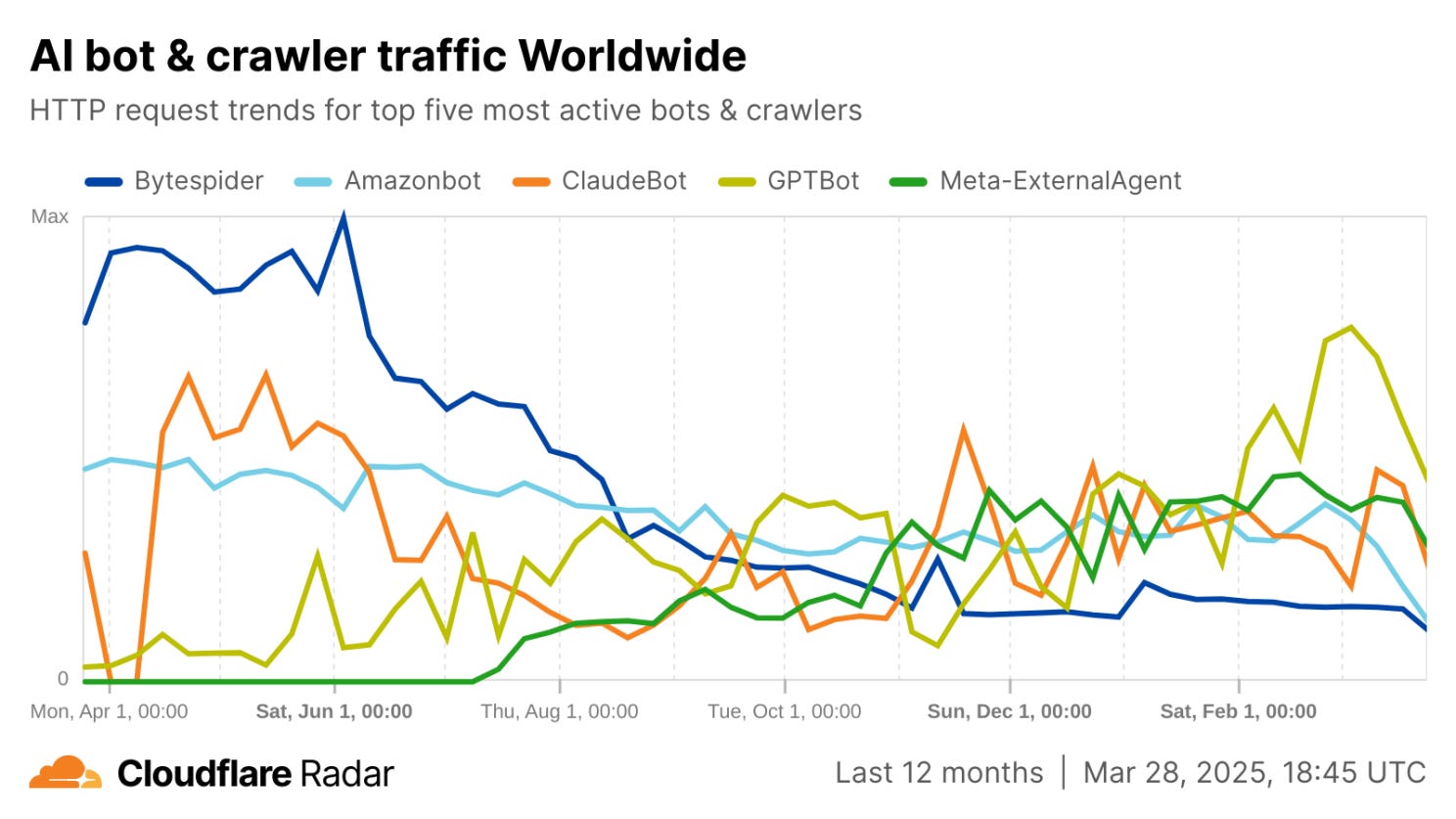
AI bots, including scrapers from major tech companies, are accelerating this shift. Tools like ChatGPT, ByteDance’s “Bytespider,” Amazon’s AWS crawler, and Anthropic’s Claude bot notoriously ingest staggering amounts of online content to train LLMs. Cloudflare found that AI scrapers were among the most active web agents: Meta’s “facebookexternalhit” bot made up 27% of AI bot requests in 2024, followed by ByteDance’s “Bytespider” crawler (23%). In a separate sample, TollBit found that AI companies scraped 160 news and tech sites ~2M times in 4Q24 alone, effectively scraping each page seven times.
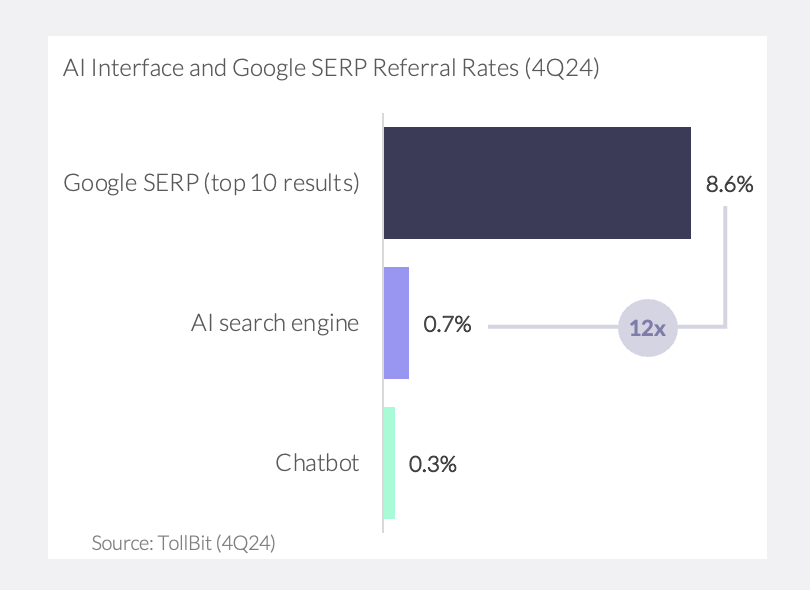
Referral traffic from AI chat is minimal. Unlike Google’s traditional crawler—which indexes pages to direct real visitors back to a website—AI chatbots deliver answers directly within the interface, slashing referral clicks. TollBit found that AI bots drove ~96% less referral traffic versus Google search. It found referral rates through AI chatbots were 0.3% and through AI search engines were 0.7%, a fraction of a standard (non-AI) Google search engine results page referral rate of 8.6% (Exhibit 3).
This isn't just a revenue problem; it's a cost problem, too. Web scraping bots request pages just like users do, consuming bandwidth and server resources but not clicking on ads or making purchases. One small site owner saw a sevenfold spike in monthly bandwidth once AI bots began hammering his pages, tripling his hosting costs with no revenue offset.
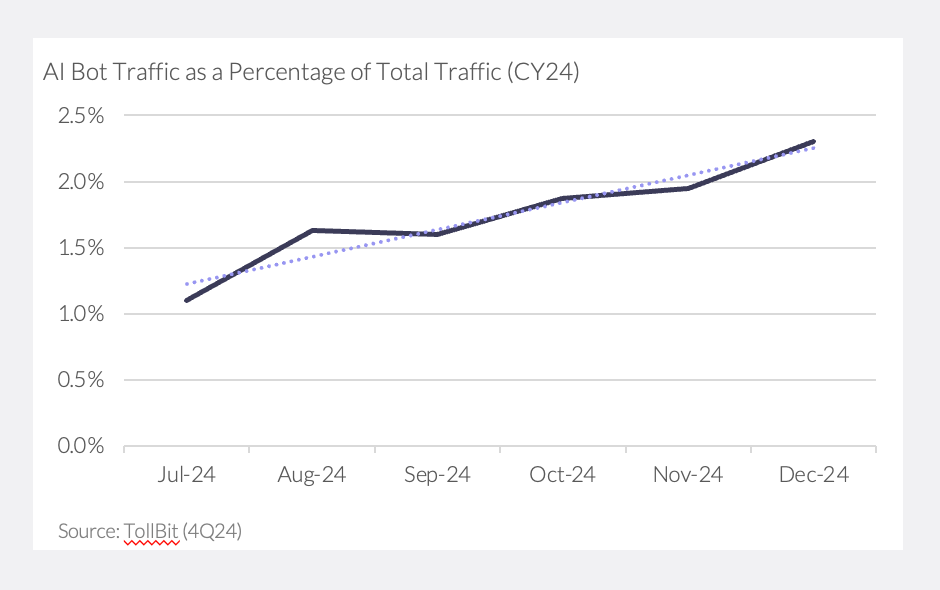
The problem is likely to get worse as AI becomes more mainstream. Gartner projects a 25% decline in traditional search engine volume as users turn to AI chat interfaces. TollBit, which monitors AI bot activity across hundreds of publishers, has seen the rate of AI scraping double from Q3 to Q4 2024 – with 2x more scrapes per website and 3x more scrapes per page. News, tech, and shopping sites are especially at risk, given their valuable and frequently updated data (Exhibit 5).
Publishers have tried blocking bots, but they often ignore the rules. A Reuters Institute study found that by late 2023, 48% of top news sites had disallowed OpenAI’s bot in their robots.txt files. Yet TollBit found 65M bot requests in 4Q24 where bots bypassed or ignored robots.txt rules altogether, a 40% jump in bots bypassing robots.txt QoQ.
Monetization is the clearest path forward. Publishers with large enough proprietary data are striking up deals with LLMs directly. OpenAI agreed to pay $16M to digital publisher Dotdash Meredith and signed a news content sharing agreement with News Corp for reportedly >$250M over five years. Thomson Reuters noted that AI content licensing agreements brought in $34M in revenues in 2024. Nearly 10% of Reddit’s $130M 2024 revenues came from licensing deals, including a ~$60M deal with Google and a deal with OpenAI.
However, these one-off agreements are not scalable. These lump-sum deals tend to occur between the largest publishers and AI firms (often under pressure of potential litigation). Many smaller publishers lack the clout to cut individual deals. Even if publishers and bot providers wanted to sign deals, the number of deals required grows quadratically.
Startups are finding ways to help the long tail of providers monetize their data assets. Players like TollBit and Skyfire are working with websites to charge bots a micropayment for website access or data scraping. TollBit has facilitated >5M transactions for its >500 publishers, including Time, Hearst, and Adweek. ProRata released Gist.ai, an AI search engine that compensates publishers based on how much their content shows up in AI-generated results and has agreements with Financial Times, Axel Springer, The Atlantic, Fortune, and Universal Music Group. Others like ScalePost and Protege are building a library of licensed content for AI teams. Traditional web infrastructure companies like bot detection services and CDNs are also getting involved: Cloudflare, HUMAN Security, and others are partnering with content owners to identify AI scrapers and funnel them toward paid access through partnerships with Skyfire and TollBit.
Early pricing models center on micropayments per content fetch. Publishers are setting rates on the order of $0.001–$0.005 per page for AI access, often benchmarking against ad revenue lost per pageview. Reddit is pricing its new API at $12,000 per 50 million calls, or $0.00024 per request.
The market opportunity for these micropayments is substantial. Global monthly internet traffic in 2024 was ~456 exabytes, with about 35% of that being non-video data and 30% coming from bots. Even if only 20% of that bot traffic is monetizable—and publishers charge around $0.001 per 2MB page—estimates land at around $60B in potential annual revenues. With internet traffic forecasted to rise 19% annually through 2029 and bot traffic gaining ~250bps of market share each year, the bot toll space could double or triple in just five years.